RAG全称Retrieval-Augmented Generation,翻译成中文是“检索增强生成”。其中检索指的是“文本相似性检索”,生成指的是“基于大语言模型的生成型算法”,比如OpenAI的GPT系列,以及阿里的通义千问系列等等。完整去理解这个术语应该是:用文本语义相似性检索的结果,来丰富大语言模型的输入上下文,以此提升大语言模型的输出效果。RAG技术之所以重要,近几年热度持续上升,其主要原因还是受大语言模型影响,尤其大语言模型技术在实际使用过程中本身存在的一些缺陷。

大语言模型的缺陷
除去模型的复杂性对数据和算力的要求太高(这顶多算是门槛高,造成一般中小型公司无法入坑),大语言模型(LLM)在实际应用过程中有两个缺陷:
(1)知识的局限性
CV领域中常见的YOLO系列检测算法,模型参数量大概在百万~千万级别。而大语言模型参数量通常十亿起步,更复杂的甚至达到了千亿万亿级别。更多的参数量意味着模型能存储(学习)更多的知识,无论从知识深度还是广度都比传统的“小”模型要更优。但是,这个世界是复杂的,不同行业的知识千差万别,俗话说:隔行如隔山,这个在大模型技术中尤为突出。通常一些公司在训练大模型时,采用的数据主要来源于互联网,大部分都是公开的知识数据,模型从这些公开的数据中学习当前数据的基本规律,但是对于那些由于各种原因没有公开到网络上的垂直细分领域的知识数据,大模型在训练过程中完全无法接触到,这也导致模型在实际应用推理过程中,对特定领域问题回答效果不佳、甚至完全一本正经的胡说八道。下面是我向ChatGPT询问“车道收费软件程序无法正常运行如何处理?”,可以看到,ChatGPT在这种专业问题中表现不足,虽然回答的条理清晰(第一张图),但是并不是我们想要的答案(第二张图)。
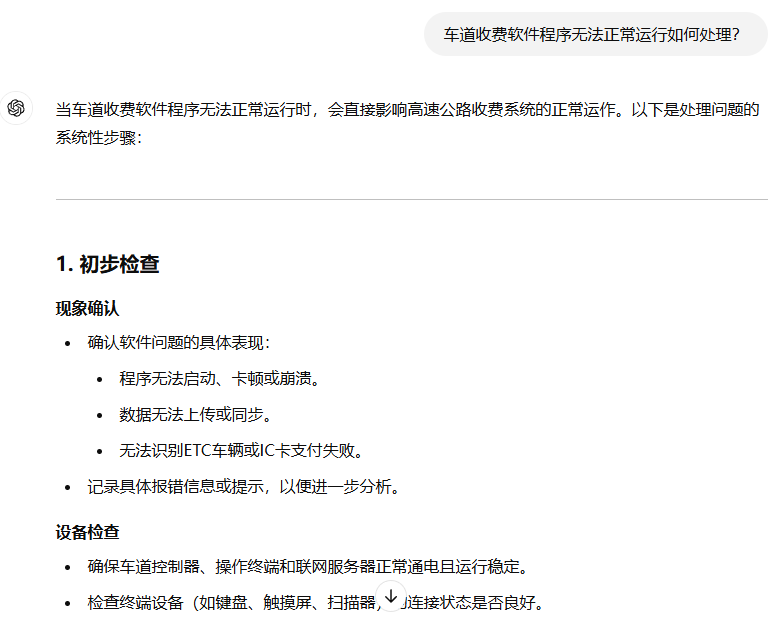
<ChatGPT回答结果↑>

<标准答案↑>
(2)知识的实时性
大模型掌握的知识受限于训练它用到的数据,模型训练(迭代)一次消耗的时间相对较长(几个月甚至一年),很多知识数据虽然是公开的,但是由于时间关系,并不能及时被大模型掌握。比如前几天(2024/12/3)网络上出现了韩国总统尹锡悦突然发动戒严的新闻,你如果向一个11月份就上线的大模型问韩国的相关历史事件,这个戒严事件肯定不在回答之列,原因很简单,因为模型在训练过程中并没有相关数据。下面是我向ChatGPT询问“韩国近现代有哪些主要的政治事件?”,在它给出的回答中,可以看到回答的主要事件截止时间在2022年尹锡悦上台后不久,回答中没有更新的数据。

<ChatGPT关于韩国近代历史事件的回答↑>
提示工程的重要性
在2022年底ChatGPT刚出来不久,GitHub上就有一个非常火爆的项目仓库叫awesome-chatgpt-prompts(截止2024/12/15已经有114K星星),这个仓库核心就是一个README文件,里面包含了我们在使用ChatGPT时常用到的一些“提示词”。提示词的作用是告诉大模型一些上下文背景,让模型能够根据你的提示词来给出想要的回答。提示词完全使用自然语言编写,好的提示词能够得到更加准确的回答。下面给出两个例子,第一个是让ChatGPT充当Linux操作系统命令行终端(类似ssh工具),响应用户输入的Linux命令;第二个是让通义千问充当一个关键信息提取器,将两个人语音对话中的关键信息提取出来然后按指定格式输出。
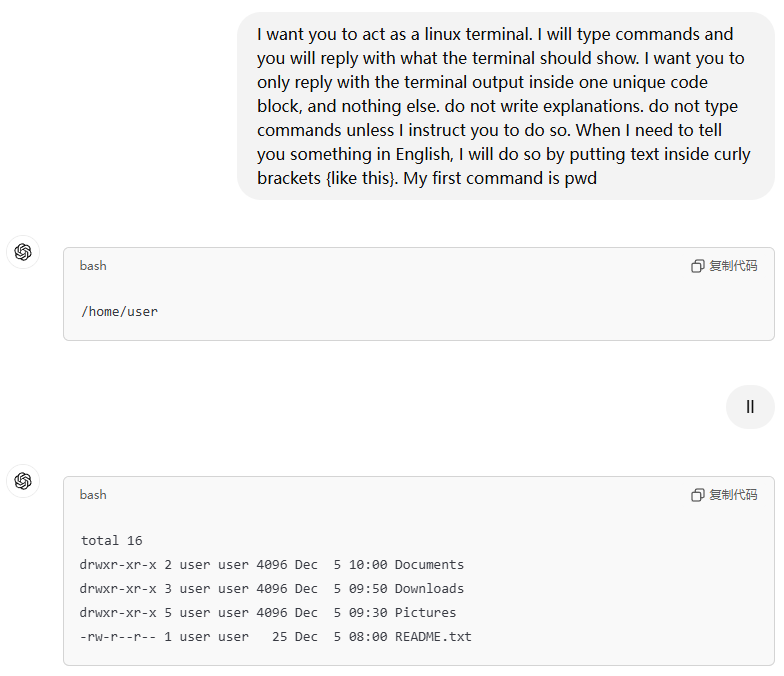
<ChatGPT扮演Linux终端↑>

<给通义千问设置提示词↑>
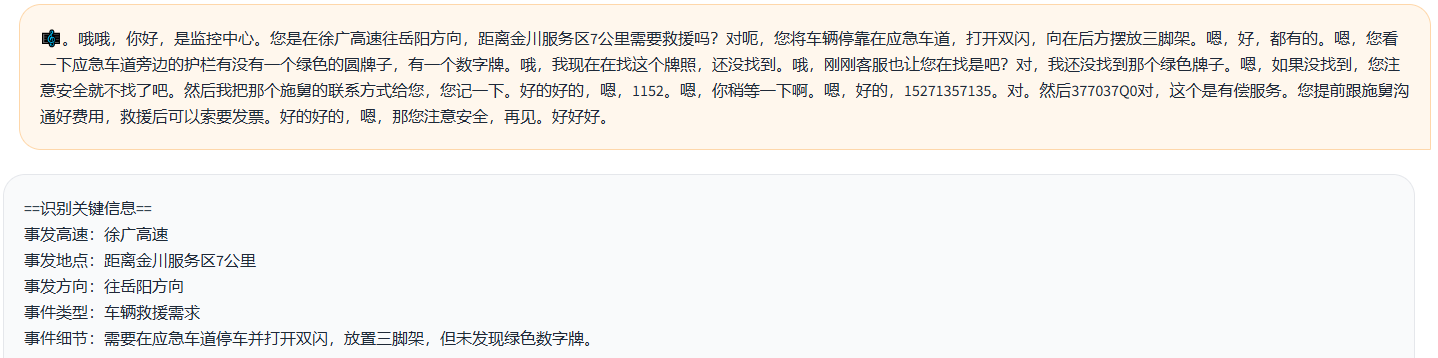
<通义千问根据提示词给出的回答↑>
可以说如何用好大模型,提示词是关键。提示词的设计可以复杂,比如提供一些输入输出的示例,让大模型参考,也可以提供“思考”逻辑或者方向,给大模型提供一些回答问题的思路,当然也可以交代一些背景知识,让大模型“实时”去消化。
既然提示词如此重要,它能够丰富大模型问答上下文,让模型了解更多的背景知识,从而提升大模型的使用效果。那么我们能否使用类似提示词这种方式去弥补前面提到的那些大模型应用缺陷呢?答案是肯定的,这就是RAG采用的技术思路。针对“知识的局限性”和“知识的实时性”问题,我们可以借用类似“提示词”之手告诉大模型,让它能够在“外部补充数据”的上下文环境中,给出我们想要的答案,从而规避知识的局限性和实时性问题。
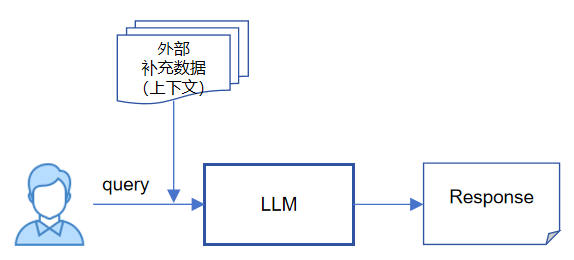
为了让大模型能够掌握额外的背景知识,我们引进了“外部补充数据”,那么我们应该如何获取这个外部补充数据呢?很明显这个获取的过程很关键,有两个原因:
1、外部补充数据一定要与用户query有关,而且相关性越高越好,否则就是误导模型思考,补充数据越详细越好,模型获取的外部信息就越充足。
2、我们事先并不知道用户需要query什么问题,所以获取外部补充数据一定是一个检索的过程,从一个大规模特定领域的非结构化数据集合中检索与query相关的部分,这个检索是实时性的,针对不同的query可能都需要这个操作。
现在我们将上一张图更新一下,大概可以修改成这样:
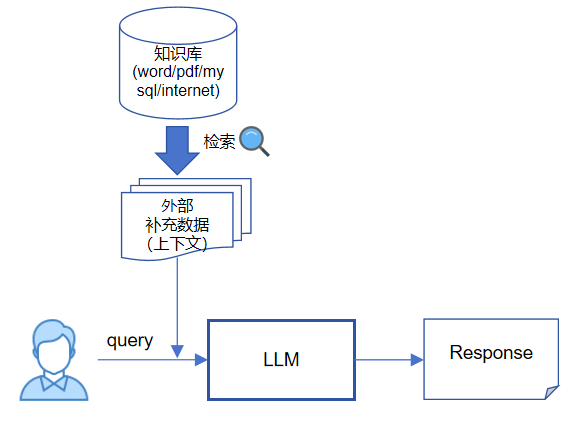
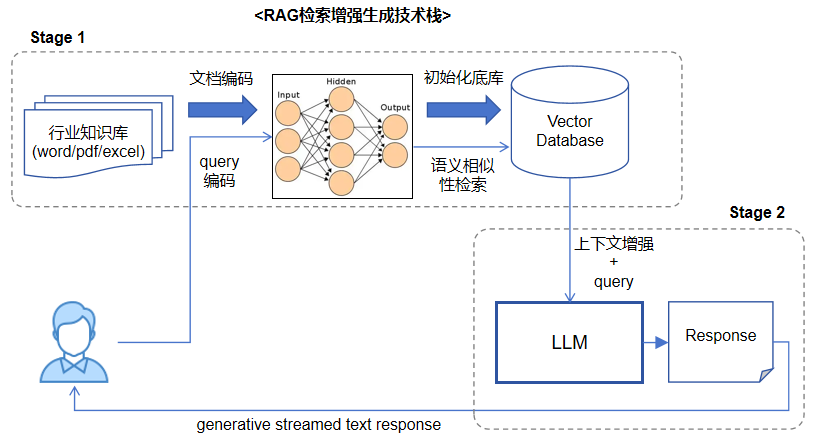
针对用户的每个query,我们先从“知识库”(大规模特定领域的非结构化数据集合,可随时更新)检索出与query相关的信息,然后再和原始query一起合并输入到大模型。目前这里的检索方式通常采用“文本语义相似性检索”,这个跟CV领域图像相似性检索类似,一般基于高维特征去做相似度匹配。
文本语义相似性检索
一般在讲语义相似性检索的时候,通常也会提到关键字检索,这是两种不同的文本检索方式。下面是两种方式特点:
1、语义相似性检索。基于文本内容含义去做匹配,算法能够理解句子(词语)的内在含义,然后找出意义与之相似的内容。比如“这个产品令人眼前一亮”和“这个产品设计很新颖”虽然文本内容本身不尽相同,但是其意义相似,那么算法认为它们相似度很高。类似的,“汽车”和“轿车”相似度很高,“跑步鞋”和“耐克”相似度很高,“晴朗的天”和“万里无云”相似度很高。
2、关键字检索。基于文本内容本身去做匹配,算法只匹配句子(词语)内容本身,“晴朗的天”和“万里无云”如果从关键字去匹配的话,相似度基本为零。在学习《数据结构和算法
》课程的时候,里面提到的“汉明距离”可以算作关键字匹配的一种方式,主要用来计算字符串之间的相似度。
我们从上面的解释可以了解到,语义相似性检索方式显得更加“聪明”,更贴近人类思考的方式,所以在RAG技术栈中,一般采用语义相似性检索的方式去获取前面提到的“外部补充数据”。文本的语义相似性检索一般基于“高维特征”去完成,大概思路就是事先对知识库中的文本内容进行特征编码,生成高维特征向量(通常128/256/512维度),最后存入专用向量数据库(比如Faiss/Milvus向量数据库),形成底库。在检索阶段,先对query文本使用相同的特征编码算法生成特征向量,然后使用该向量去向量数据库中检索前TOP N个相似特征,最后映射回前TOP N个原始文本内容。那么得到的这些原始文本内容,就和query文本在语义上存在很高的相似度。
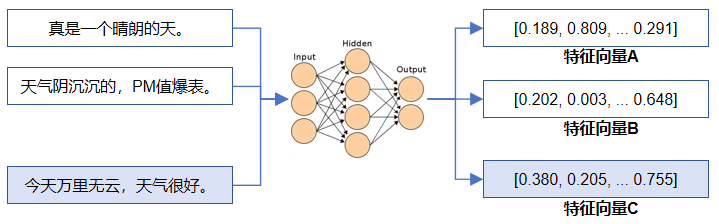
上面图中,A和B是特征向量底库,C是query特征向量,最终C和A之间的相似度要比C和B之间更高,所以“今天万里无云,天气很好”可以匹配到“真是一个晴朗的天”。那么如何衡量特征向量之间的相似度呢?以2维向量为例(3维或更高维类似),可以把特征向量看做是二维坐标系中的一个点,最后计算两点之间的距离,通常有两种距离计算方式,一个叫“欧氏距离(直线距离)”,一个叫“余弦距离”。
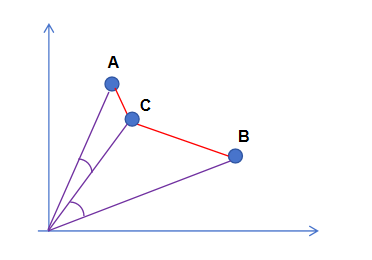
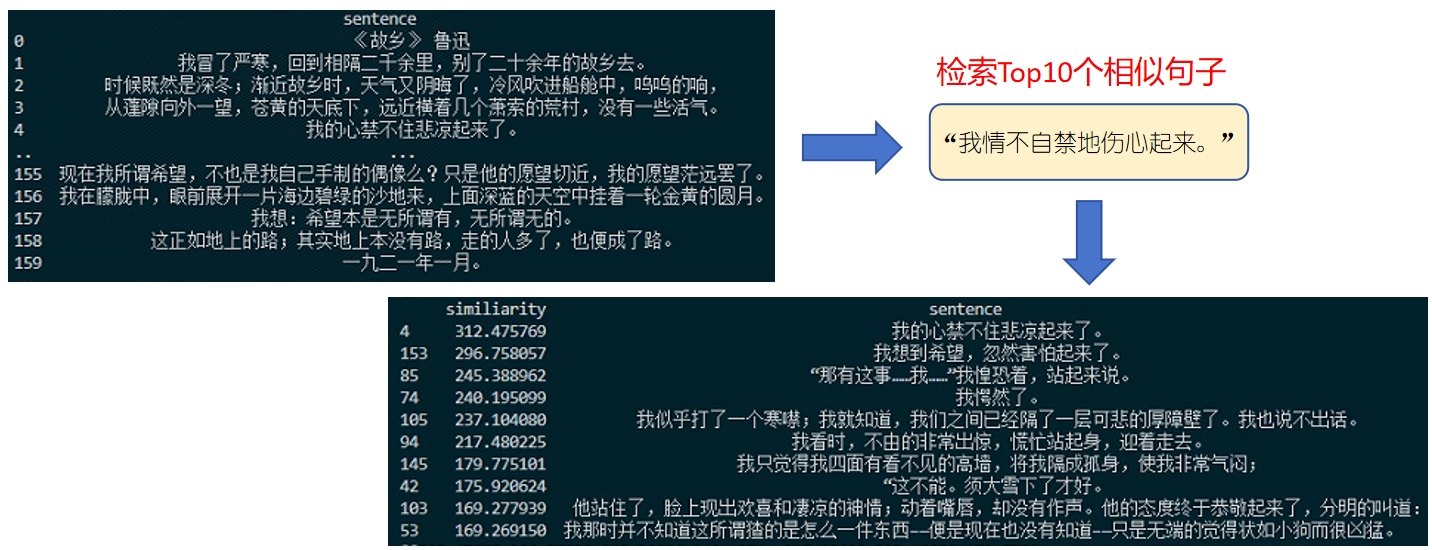
欧氏距离越小,两个点越靠近,代表越相似(图中红色);余弦距离代表的是点与原点连线之间的夹角,夹角越小(余弦值越大,图中紫色),代表越相似。(关于特征编码,以及特征相似度计算可以参考之前的文章)。目前网络已经有很多开源的文本特征编码模型,针对不同国家语言,可以为其提取文本特征标识。下面是我对鲁迅的《故乡》全文做特征编码,然后去检索“我情不自禁地伤心起来。”这句话的例子,最后返回TOP 10个与之语义相似的句子,可以看到整体表现还算可以,尤其排名靠前的几个结果,基本和query句子的含义比较接近。
从“单阶段推理”到“两阶段推理”
我们现在回顾一下大语言模型的工作流程,基本上就是用户提供query问题输入(可以携带一些简单的上下文,比如历史对话记录),大模型直接给出回答,注意这里大模型完全基于训练时积累的经验给出的答案。这个可以看做是一个“端到端”的推理过程,我们称之为“单阶段推理”(可以类比CV领域中经典的YOLO系列检测算法)。那么相比较而言,RAG就是“两阶段推理”,问答系统先要从知识库中检索与用户query有关的信息,然后再与query一起,传入大模型,之后的流程就和单阶段推理一致。以此可以看出,RAG指的并不是具体哪一个算法或者技术,而是一套解决问题的技术方案,它需要用到文本特征编码算法、向量数据库、以及大语言模型等等。Github上有很多RAG相关的框架,都提供了灵活的接口,可以适配不同的文本编码模型、不同的向量数据库、不同的大语言模型。
总结RAG的优劣势和应用场景
1、RAG的优势
可以有效解决单纯使用大语言模型时碰到的一些问题,比如知识的局限性和实时性,能够解决大模型在垂直细分领域落地的难题,让大模型更接地气、给出的回答更贴近标准答案而不是一本正经的胡说八道。同时,让中小型企业可以基于开源大模型快速搭建自己的知识库问答(建议)系统,而无需对其进行二次训练或微调(算力和数据,包括大模型的训练门槛都是相当之高)。
2、RAG的劣势
引入了更多的技术栈,提升了系统的复杂性,无论开发还是后期维护工作量更高。同时,由于前期引入了“语义检索”的流程,涉及到准确性问题,一旦前期检索环节出问题,直接影响后面大模型效果。
3、RAG应用场景
RAG可以用在垂直细分领域的知识问答(建议)场景,对数据隐私要求比较高,同时对知识库实时更新有要求。当然除了本文介绍的这种基于知识库问答系统,类似的还可以用在基于数据库、基于搜索引擎等问答系统,原理基本类似。