(2019年文章)
大部分介绍神经网络的文章中概念性的东西太多,而且夹杂着很多数学公式,读起来让人头疼,尤其没什么基础的人完全get不到作者想要表达的思想。本篇文章尝试零公式(但有少量数学知识)说清楚什么是神经网络,并且举例来说明神经网络能干什么。另外一些文章喜欢举“根据历史交易数据预测房子价值”或者“根据历史数据来预测未来几天是否下雨”的例子来引入“机器学习/深度学习/神经网络/监督学习”的主题,并介绍他们的作用,这种例子的样本(输入X输出Y)都是数值,数字到数字的映射,简单易懂,但是现实应用中还有很多场景并非如此,比如本文后面举的“图像分类”例子,输入是图片并不是简单的数值输入。
分类和回归
我们平时讨论的机器学习/深度学习/神经网络大部分时候说的是“监督学习”范畴,监督学习应用最为广泛,也是神经网络发挥巨大作用的领域,因此,本文所有内容都是基于监督学习。从带有标签的样本数据中学习“经验”,最后将经验作用于样本之外的数据,得到预测结果,这就是监督学习。监督学习主要解决两大类问题:
(1)分类
分类很好理解,就是根据输入特征,预测与之对应的分类,输出是离散数值,比如明天是否下雨(下雨/不下雨)、短信是否是垃圾短信(是/否)、图片中包含的动物是猫、狗还是猴子(猫/狗/猴子)等等。分类模型的输出一般是N维向量(N为分类数),每个向量值代表属于此分类的概率。
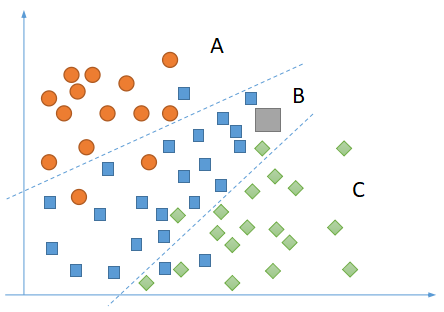
如上图,根据样本数据(黄色圆形、蓝色正方形、绿色棱形),监督学习可以确定两条边界线,对于任何样本之外的数据(图中灰色正方形),可以预测它所属分类为B,对应的预测输出可以是[0.04, 0.90, 0.06],代表属于A类的概率为0.04,属于B类的概率为0.90,属于C类的概率为0.06,属于B类的概率最大,因此我们可以认为它的分类为B。请注意图中用来划分类型区域的两条虚线,同类样本并没有完全按照虚线分割开来,有黄色的圆形被划分到B类中,也有蓝色的正方形被划分到A类中。这种情况之所以出现,是因为监督学习得到的经验应该具备一定程度的泛化能力,所以允许学习过程中出现一定的误差,这样的学习才是有效的。
(2)回归
与分类相反,回归主要解决一些输出为具体数值的问题,比如明天的气温(20、21、30等)、明天股票开盘价(100、102、200等)。回归模型的输出一般是具体数值(包含向量,向量中包含每个具体的数值)。
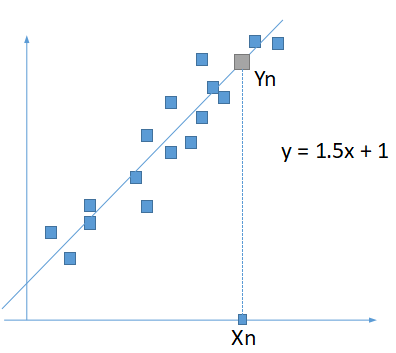
如上图,根据样本数据(图中蓝色正方形,平面坐标系点),监督学习可以确定一条直线y=1.5x+1,对于任何样本之外的输入(Xn),可以预测对应的输出Y为1.5*Xn+1。请注意通过监督学习得到的直线y=1.5*x+1,事实上并不是每个样本都刚好落在该条直线上,大部分分布在直线周围。原因跟上面提到的一样,监督学习过程允许出现一定的误差,这样才是有效的学习。
学习的过程
不管是分类还是回归问题,监督学习都是从样本数据中学习经验,然后将经验应用到样本之外的数据。那么这个经验具体指什么?学习的本质是什么呢?
以上面回归问题为例,我们得到直线y=1.5*x+1的过程如下:
(1)确定样本数据呈直线分布(近似直线分布);
(2)设定一个目标函数:y=w*x+b;
(3)调整w和b的值,使样本数据点尽可能近地分布在直线周围(可以使用最小二乘法);
(4)得到最优的w和b的值。
以上是4步完成学习的过程,这个也是最简单的监督学习过程。至于其中“如何确定样本呈直线分布”、“如何判断目标函数为y=w*x+b”以及“如何去调整w和b的值,可以使样本数据点尽可能近的分布在直线周围”这些问题,后面一一介绍。
我们经常听到的深度学习中模型训练,其实指的就是学习的过程,最后输出的模型中主要包含的就是w和b的值,换句话说,训练的过程,主要是确定w和b的值,可以称这些参数为“经验”。
监督学习的过程就是找出X->Y的映射关系,这里的输入X可以称之为“特征”,特征可以是多维的,实际上X大多数情况都是多维向量,类似[1, 1.002, 0.2, …],输出Y称为“预测值”,预测值也可以是多维的,类似[0.90, 0.08, 0.02],比如前面提到的分类问题中,输出Y为多维向量,每个向量值代表预测对应分类的概率大小。
全连接神经网络
全连接神经网络由许许多多的“神经元”连接而成,每个神经元可以接收多个输入,产生一个输出,类似前面提到的X->Y的映射,如果输入是多维的,格式就是[x1, x2, …, xn]->Y(对于单个神经元来讲,输出都是一个数值)。多个神经元相互连接起来,就形成了神经网络,神经元的输入可以是来自其他多个神经元的输出,该神经元的输出又可以作为其他神经元的输入(的一部分)。下图为一个神经元的结构:
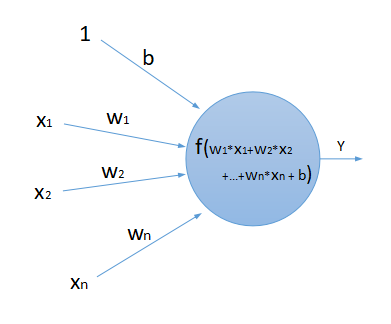
如上图所示,一个神经元接收[x1, x2, …, xn]作为输入,对于每个输入Xi,都会乘以一个权重Wi,将乘积结果相加再经过函数f作用后,产生输出Y。多个神经元相互连接之后,得到神经网络:
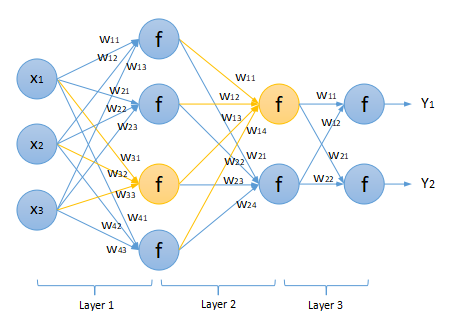
如上图,多个神经元相互连接起来组成全连接神经网络(图中只包含w参数,省略了b),图中神经网络一共包含3层(Layer1,Layer2和Layer3),上一层每个神经元的输出全部作为后一层每个神经元的输入,这种网络叫“全连接神经网络”(顾名思义,全连接的意思)。图中黄色部分就是两个完整的神经元结构,第一个神经元有三个输入(x1,x2和x3),分别乘以对应的权重w31,w32和w33,第二个神经元有四个输入(分别来自于Layer1层中的4个输出)。该神经网络可以接受一个3维向量作为输入(格式为[x1, x2, x3]),从左往右计算,最后输出一个2维向量(格式为[y1, y2])。对应它学习到的经验,可以用来处理符合如下映射关系的“分类”或者“回归”问题:
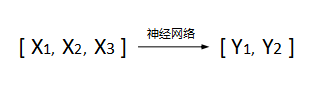
全连接神经网络是结构最简单的神经网络,相邻两层之间的神经元每个之间都有连接,因为结构最简单,因此通常以它作为入口来介绍其他结构更复杂的网络。注意,大部分神经网络并不是每个神经元都有连接关系,而且有些并不是严格遵从“数据从左往右移动”这种顺序。
神经网络中的矩阵计算
对于单个神经元的计算过程而言,是非常简单的,分三步:
(1)计算每个输入参数Xi和对应权重Wi的乘积;
(2)将乘积加起来,再加上一个偏移值b;
(3)最后将函数f作用在(2)中的结果上,得到神经元的输出。
但是对于神经网络这种包含大量的神经元而言,如何可以更加方便、代码中更简洁地去实现呢?答案是使用矩阵,线性代数搞忘记的同学也不要紧,这里仅仅是利用了“矩阵相乘”和“矩阵相加”的规则。
(1)矩阵相加
矩阵相加要求两个矩阵维度相同,矩阵中对应的数字直接相加即可,生成一个新的矩阵,维度跟之前一样:

(2)矩阵相乘
矩阵相乘要求第一个矩阵包含的列数和第二个矩阵包含的行数相同,M*N的矩阵乘以N*T的矩阵,得到M*T的一个新矩阵:
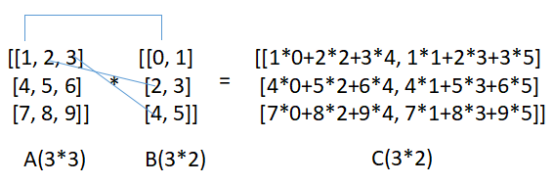
第一个矩阵A的第一行每个元素与第二个矩阵B的第一列各个元素相乘然后加起来,作为结果矩阵C中的第一行第一列,第一个矩阵A的第一行每个元素与第二个矩阵B的第二列各个元素相乘然后加起来,作为结果矩阵C中的第一行第二列,以此类推。上图中3*3的矩阵乘以3*2的矩阵,得到一个3*2的新矩阵。如果将上图7中A矩阵换成神经网络中的参数W(W11,W12,W22…),将B矩阵换成输入X特征(X1, X2, X3…),那么全连接神经网络中每一层(可以包含多个神经元)的计算过程可以用矩阵表示成:
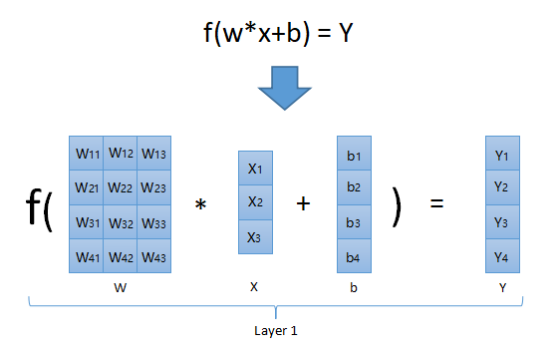
如上图,使用矩阵我们可以批量操作。对于图4中第一层(Layer1)所有神经元的计算过程,可以通过图8一次性计算完成。图中W矩阵先和X矩阵相乘,再加上偏移值B矩阵,得到一个中间结果(也是一个矩阵),然后再将中间结果传给函数f,输出另外一个新矩阵Y,那么这个Y就是神经网络第一层Layer1的输出,它会作为下一层Layer2的输入,后面以此类推。注意,函数f接受一个矩阵为参数,并作用于矩阵中每个元素,返回一个维度一样的新矩阵,后面会提到。可以看到,之前需要计算4次f(w*x+b),现在只需要一次就可以了。
通过前面的介绍,可以得知,神经网络的训练过程就是找到最合适的W矩阵(多个)和最合适的b矩阵(多个)使得神经网络的输出与真实值(标签)最接近,这个过程也叫做模型训练或者调参(当然模型训练远不止这样,还有其他诸如超参数的确定)。
非线性变换
即使输入是高维向量,经过简单的W*X+b这样处理之后,输出和输入仍然呈线性关系。但是现实场景中大部分待解决的问题都不是线性模型,因此我们需要在输入和输出之间增加一个非线性变换,也就是前面多次提到的f函数(又称为激活函数)。由于各种原因(这里涉及到神经网络具体的训练过程,反向传播计算权重值,暂不过多解释),常见可用的激活函数并不多,这里举两个函数为例:
(1)Sigmoid函数
Sigmoid函数能将任意实数映射到(0, 1)之间,具体函数图像如下:
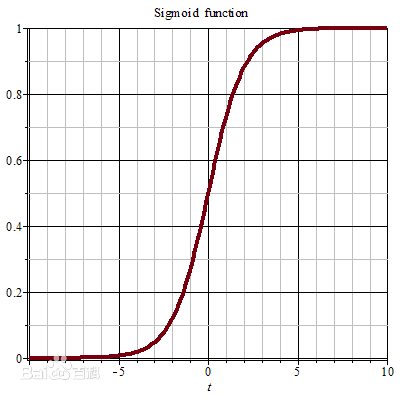
上图中Sigmoid函数将任意输入映射到(0, 1)之间的值,因此Sigmoid函数又经常被称为逻辑函数,常用于二分类预测问题,假设有两个分类A和B,对于任何输入特征X,Sigmoid返回值越趋近于1,那么预测分类为A,反之则为B。
(2)ReLu函数
ReLu函数很简单,返回值为max(x, 0),具体函数图像为:
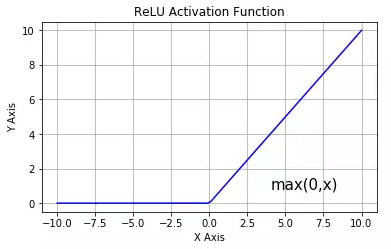
上图中ReLu函数将任意输入的负数转换为0,其他输入原样输出。ReLu函数是目前深度学习中应用最多的激活函数,具体原因这里不做解释。这里需要说一下,深度学习/神经网络中有些东西并没有非常充足的理论依据,完全靠前人经验总结而来,比如这里的ReLu函数看似简单为什么在大部分场合下效果最好,或者神经网络训练中神经元到底如何组织准确性最高等等问题。
神经网络解决分类问题
经过前面的介绍不难得出,神经网络可以解决复杂映射关系的“分类”问题。将特征输入到神经网络,经过一系列计算得到输出。下图举一个形象的例子来说明神经网络如何解决分类问题:
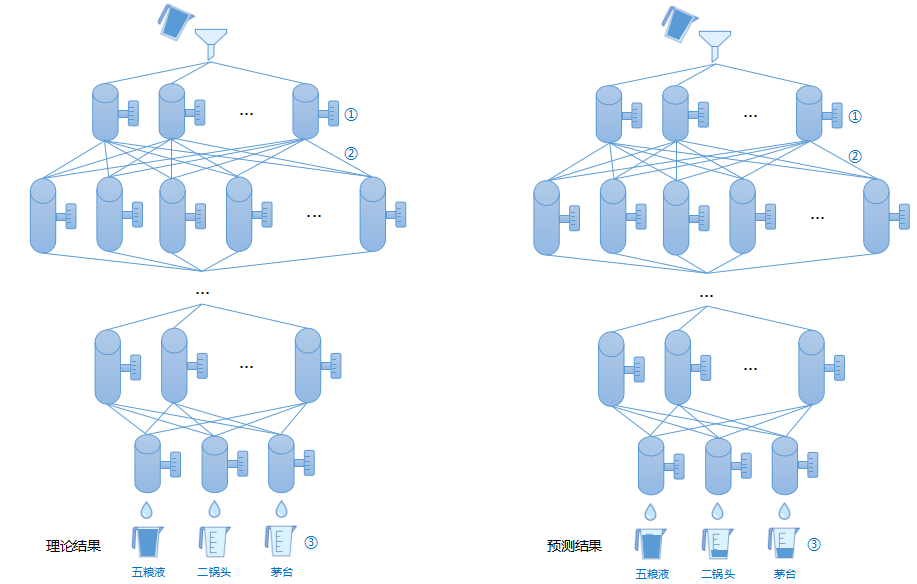
上图显示一个和全连接神经网络同样结构的管道网状结构,从上到下有多个阀门可以调节控制液体走向(图中①),经过事先多次样本液体训练(使用不同品牌、不同酒精度、不同子型号的白酒),我们将阀门调节到最佳状态。随后将一杯白酒从最顶部倒入网状结构,最后经过管道所有液体会分别流进三个玻璃杯中(图中③)。如果我们将一杯五粮液倒入管道,理论情况所有的液体应该完全流进第一个玻璃杯中(图中左侧),但是实际上由于神经网络具备泛化能力,对于任何输入(包括训练样本),大部分时候不会跟正确结果100%一致,最终只会保证第一个玻璃杯中的液体最多(比如占85%),其余两个玻璃杯同样存在少量液体(图中右侧)。
那么现在有个问题,神经网络最后输出的是数值(或多维向量,向量包含具体数值),结果是如何体现“分类”的概念呢?本文最开始讲到过,分类问题最后都是通过概率来体现,某个分类的概率最高,那么就属于该分类,下图显示如何将数值转换成概率:
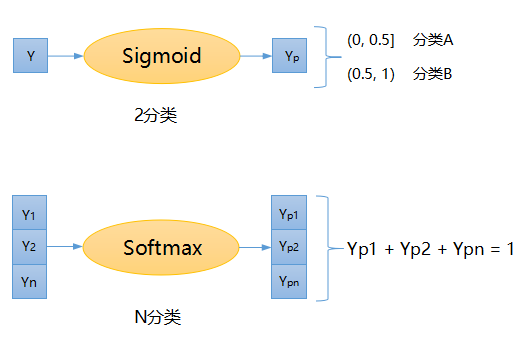
如上图所示,对于2分类问题,我们通常使用前面提到的Sigmoid函数将其转换成(0,1)之间的概率值,然后再根据概率值划分类别。对于N分类(N也可以为2),我们要使用另外一个函数Softmax,该函数接受一个向量作为参数,返回一个新向量,维度跟输入一致,新向量的每个值均分布在在(0, 1)之前,并且所有概率之和为1。注意该函数作用在整个向量上,向量中的每个值之间相互有影响,感兴趣的同学上网查一下公式。
图像分类任务
图像分类又称为图像识别,给定一张图,要求输出图中包含的目标类型,比如我们常见的“微软识花”、“识别猫还是狗”等等,这是计算机视觉中最典型的“分类”问题。图像分类是其他诸如“目标检测”、“目标分割”的基础。
(1)图像的定义
数字图像本质上是一个多维矩阵,常见的RGB图像可以看作是3个二维矩阵,矩阵中每个值表示对应颜色通道上的值(0~255),还有其他比如灰度图,可以看作是是1个二维矩阵,矩阵中每个值表示颜色的像素值(0~255)。
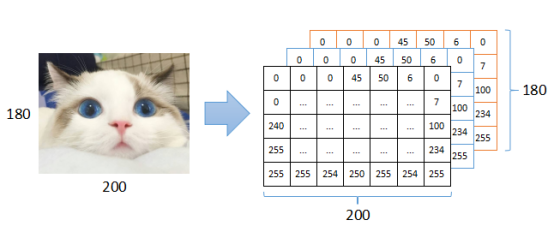
如上图所示,一张RGB全彩数字图片大小为180*200,对应3个矩阵,大小都是180*200,矩阵中的数值范围都在0~255。对于单通道灰度图而言,对应1个矩阵,大小也是180*200:
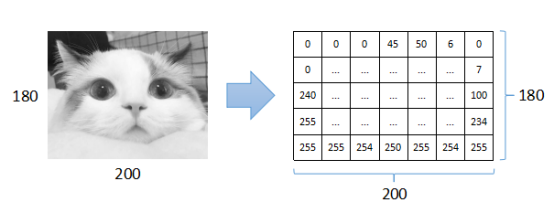
(2)使用全连接神经网络做图像分类
前面已经讲到如何使用全连接神经网络解决“分类”的问题,图像分类同样属于分类问题,因此也可以使用神经网络的方式解决,唯一的区别是前面提到的都是数值特征输入[x1, x2, x3, …],那么对于图像而言,该将什么输入给神经网络呢?答案是图像矩阵,图像矩阵中包含数值,将一个M*N的二维矩阵展开后,得到一个M*N维向量,将该向量输入神经网络,经过神经网络计算,输出各个分类概率。下面以“手写数字图像识别”为例,介绍全连接神经网络如何做图像分类。手写数字图像识别是深度学习中的一个HelloWorld级的任务,大部分教程均以此为例子讲解图像识别,下图为手写数字图片:

上图显示4张手写数字图片,分别为“5”、“0”、“4”、“1”,每张图片大小为28*28,即长宽都为28像素,图片都是灰度图像,也就是说每张图片对应1个28*28维矩阵,将该矩阵展开得到一个28*28维向量,直接输入到全连接神经网络中。从0到9一共10个分类,因此神经网络的输出是一个10维向量。
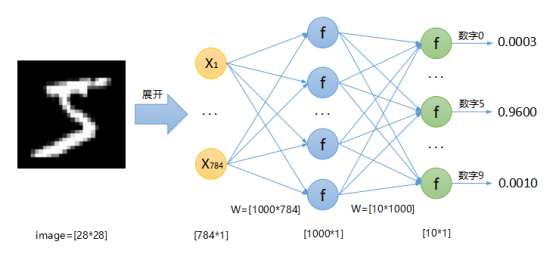
如上图所示,原始输入图片大小为28*28,将其展开成[784*1]的特征X传入神经网络。神经网络一共包含两层,第一层W矩阵大小为[1000*784],W*X之后得到大小为[1000*1]的输出,该输出作为第二层的输入X,第二层W矩阵大小为[10*1000],W*X之后得到大小为[10*1]的输出,该输出(经过Softmax作用后)即为数字0~9的概率。
注意上面定义的神经网络结构中,只包含两层(图中蓝色和绿色,黄色部分不算),第一层的W矩阵尺寸为[1000*784],这里的1000是随意设定的,可以是500甚至2000,它和神经元数量保持一致。第二层的W矩阵尺寸为[10*1000],这里的1000跟前面一样,这里的10是分类数,因为一共10个分类,所以为10,如果100分类,这里是100。神经网络的层数和每层包含的神经元个数都可以调整,这个过程就是我们常说的“修改网络结构”。
通过上面的方式做手写数字图片识别的准确性可能不高(我没有试验过),即使已经很高了它也不是一种非常好的方式,这种方式也许对于手写数字图片识别的任务很有效,但是对于其他图片比如猫、狗识别仍然很有效吗?答案是否定的,原因很简单:直接将整张图片的数据完全输入到神经网络中,包含的特征太复杂,或者噪音太多,这种现象可能在手写数字这种简单的图片中有效,一旦换成复杂的图片后可能就不行了。那么针对一般图像分类的任务,在将数据传到神经网络进行分类之前,我们还需要做什么呢?
(3)图像特征
图像特征在计算机视觉中是一个非常非常重要的概念,它在一定程度上可以当作图片的特定标识,每张图片都包含一些人眼看不到的特征。关于图像特征的介绍,大家可以参考我之前的一篇博客:https://www.cnblogs.com/xiaozhi_5638/p/11512260.html
在使用神经网络对图片进行分类之前,我们需要先提取图像特征,然后再将提取到的特征输入到全连接神经网络中进行分类,因此解决图像分类问题的正确神经网络结构应该是这样的:
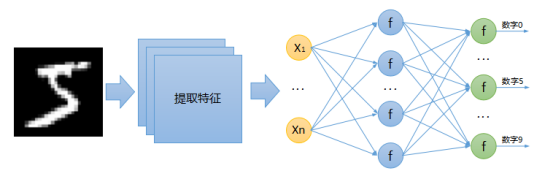
如上图所示,在全连接神经网络之前增加了一个模块,该模块也是神经网络的一部分,同样由许许多多的神经元组成,但是可能不再是全连接这种结构了,它可以自动提取图片特征,然后将特征输入到后面的全连接网络进行分类,我们通常把这里的全连接网络称为“分类器”(是不是似曾相识?)。这样一来,全连接网络的输入特征大小不再是[784*1]了(图中黄色部分),而应该根据前面的输出来定。图中这种由全连接神经网络(分类器)和特征提取部分组合起来的神经网络有一个专有名词,叫“卷积神经网络”,之所以叫“卷积”,因为在提取特征的时候使用了卷积操作,具体后面介绍。
卷积神经网络
卷积神经网络中包含一个特征提取的结构,该结构主要负责对原始输入数据(比如图像,注意还可以是其他东西)进行特征提取、抽象化、降维等操作,它主要包括以下几个内容:
(1)卷积层
卷积层主要负责特征提取,它使用一个卷积核(一个小型矩阵)以从左到右、从上到下的顺序依次作用于原始输入矩阵,然后生成一个(或多个)新矩阵,这些新矩阵我们称之为feature maps。具体操作过程如下图:
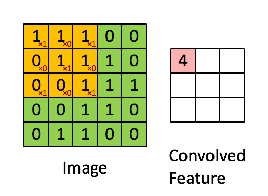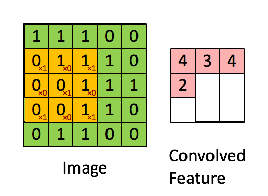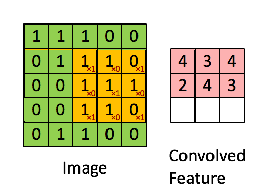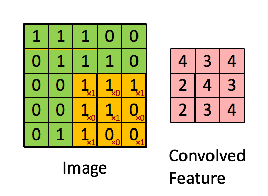
如上图所示,图中绿色部分为原始输入矩阵,黄色矩阵为卷积核(一个3*3的矩阵),经过卷积操作后生成一个新的矩阵(粉色),该矩阵称为feature map。卷积核可以有多个,每个卷积核不同,同一个输入矩阵经过不同的卷积核处理之后会得到不同的feature map。因此在卷积层中,存在多个卷积核处理之后就会生成多个feature maps,这些feature map各不相同,每个都代表一定的特征。
如果原始输入矩阵是一张图片,经过卷积核处理之后,生成的多个feature maps虽然仍然是矩阵的形式,但是不能再把它们当作图片来对待。下图显示一张图片经过两个不同的卷积核处理之后生成的两个feature maps,我们用工具将这两个feature maps以图片的形式显示出来:

如上图所示,一张原始图片经过一次卷积处理之后,生成的feature map以图片的方式显示出来之后似乎还是可以人眼识别出来。但是,如果经过多次卷积处理之后,那么最终的feature map就无法人眼识别了。上图还可以看出,不同的卷积核处理同一张输入图片后,生成的feature map之间有差别。
这里再次强调,虽然经过卷积操作得到的feature maps仍然可以以图片的形式显示出来,但是它不在是我们通常理解中的“图片”了。虽然人眼看不再有任何意义,但是对于计算机来讲,意义非常重大。卷积层可以存在多个,一个卷积层后面可以紧跟另外一个卷积层,前一层的输出是下一层的输入。卷积层中的一些参数,比如卷积核矩阵中的具体数值,都需要通过训练得到,这个道理跟前面提到的W和b参数一样,也是需要通过训练去拟合。
(2)非线性变换(激活函数)
和前面讲全连接神经网络一样,经过卷积层处理之后生成的feature maps仍然需要进行非线性转换,这里的方式跟前面一样,使用常见的激活函数,比如ReLu函数作用在feature map上的效果如下图:

如上图,feature map经过激活函数处理之后,得到另外一个矩阵,我们称之为 Rectified feature map。根据前面介绍ReLu的内容,我们可以得知,该激活函数(max(0, x))将原feature map矩阵中的所有负数全部变成了0。
(3)池化层
只有卷积操作和激活处理还是不够,因为到目前为止,(Rectified) feature maps包含的特征数据还是太大,为了让模型具备一定的泛化能力,我们需要对feature maps进行降维,这个过程称之为池化:
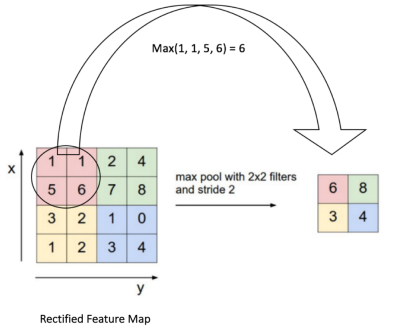
如上图,池化层在原始feature maps上进行操作,还是按照“从左往右从上到下”的顺序,选择一个子矩阵(图中圆圈部分2*2,类似前面的卷积核),选取该子矩阵范围内最大的值作为新矩阵中的值,依次处理后最后组成一个全新矩阵,这个全新矩阵尺寸比原来的小。除了取最大值外,还有取平均值和求和的做法,但是经过前人实践证明,取最大值(最大池化)效果最好。
经过池化层处理之后的feature maps仍然可以以图片的方式显示出来,还是和前面一样,人眼已经分不清是啥了,但是对于计算机来讲意义重大。
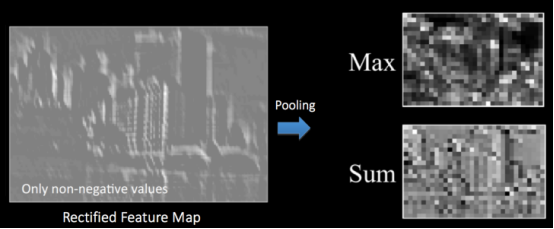
如上图所示,一张feature map经过两种方式池化,取最大值和求和,分别得到不同的新矩阵,然后将新矩阵以图片的方式显示出来,可以看到差别还是非常大(虽然人眼已经分不清内容)。
通常情况下,卷积层后面不需要都紧跟一个池化层,可以经过多个卷积层之后再加一个池化层,也就是说,卷积和池化可以不按照1:1的比例进行组合。卷积神经网络中特征提取部分就是使用卷积层、激活处理、池化层等组合而成,可以根据需要修改相应网络层的数量(通常所说的“调整网络结构”)。最后一个池化层输出的结果就是我们提取得到的图像特征,比如最后一个池化层输出T个矩阵(feature maps),每个大小为M*N,那么将其展开后得到一个T*M*N维向量,那么这个向量就是图像特征。到这里应该就很清楚了,我们如果将这个特征向量传到一个“分类器”中,通过分类器就可以得到最终的分类结果,分类器可以使用前面讲到的全连接神经网络。
(4)全连接层(分类器)
其实看到这里的同学,如果前面的内容都看懂了,这块就不难了。图像特征已经得到了,直接将它输入到全连接神经网络中去,就可以得到最终分类结果。下图显示将一个手写数字图片传入卷积神经网络中的过程,先分别经过两个卷积层和两个池化层(交叉相连而成,图中忽略了激活处理等其他操作),然后将最后一个池化层的输出先展开再作为全连接网络的输入,经过两个全连接层,最终得到一个10*1的输出结果。
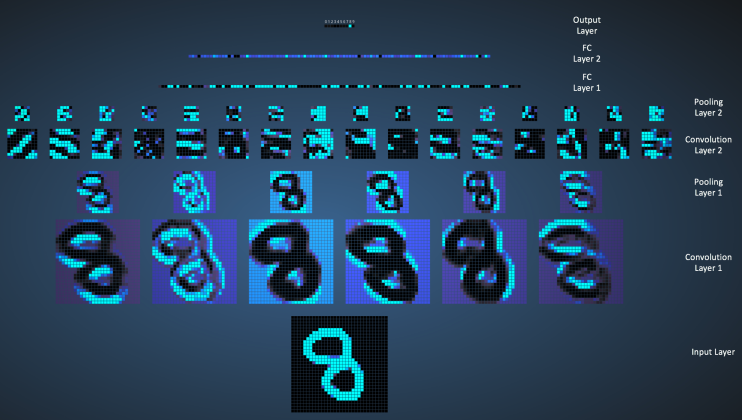
关于卷积神经网络的配图均来自:https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
关于模型训练
一些深度学习框架会帮我们去做模型训练的具体工作,比如上面提到的w和b的确定,找出最合适的w和b尽量使预测值与真实值之间的误差最小。下面举个例子,使用tensorflow来优化 loss=4*(w-1)^2这个函数,找到最合适的w使loss最小:
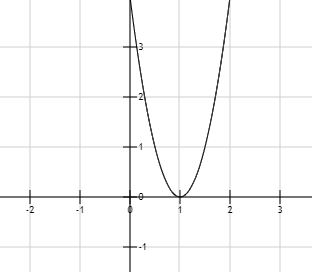
如上图所示,我们学过的数学知识告诉我们,w等于1时loss最小,这个过程可以通过求导得出(导数等于0的时候)。那么使用tensorflow来帮我们确定w该是怎样呢?下面是使用tensorflow来优化该函数,确定最有w的值:
w = tf.get_variable(“w”, initializer = 3.0)optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)for i in range(5):optimizer.minimize(lambda: 4*(w-1)*(w-1))print(w.numpy())
1.4
1.0799999
1.016
1.0032
1.00064
我们可以看到,经过5次寻找,我们得到最优的w为1.00064,已经非常接近1了。这个过程其实就是深度学习框架训练模型的简单版本。
注意:
- 本篇文章没有涉及到具体模型训练的原理,也就是求W和b矩阵的具体过程,因为该过程比较复杂而且涉及到很多数学公式,读者只需要知道:模型训练的本质就是使用大量带有标签的样本数据找到相对比较合适的W和b矩阵,之后这些矩阵参数可以作用于样本之外的数据。
- 深度学习很多做法缺乏实际理论依据,大部分还是靠经验,比如到底多少层合适,到底用什么激活函数效果更好,很多时候针对不同的数据集(或者问题)可能有不同的答案。
- 除了名字相同外,深度学习中的神经网络跟人脑神经网络工作原理没有关系,之前以为有关系,所以取了一个类似的名字,后来科学家发现好像没什么关系,因为人脑太复杂。