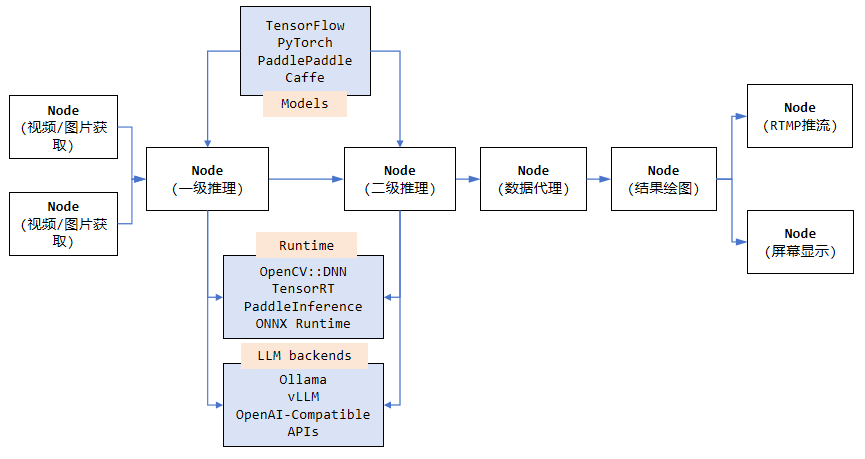
VideoPipe视频分析框架开源至今受到了很多人的好评,也有很多成功的商业落地案例。Github仓库中的Sample代码默认只支持CPU和英伟达两种硬件类型(推理部分基于OpenCV::DNN和TensorRT后端),由于某些保密原因,其他硬件平台的适配代码没有公开。随着国产信创化的需求越来越多,国产硬件也是今后AI算法部署落地的新趋势。本篇文章简要介绍如何将VideoPipe移植、适配到不同AI硬件平台,比如华为昇腾、寒武纪、瑞芯微等。
框架移植到不同硬件平台的工作主要涉及到两大块:编解码和模型推理,这两块需要对应的硬件加速。
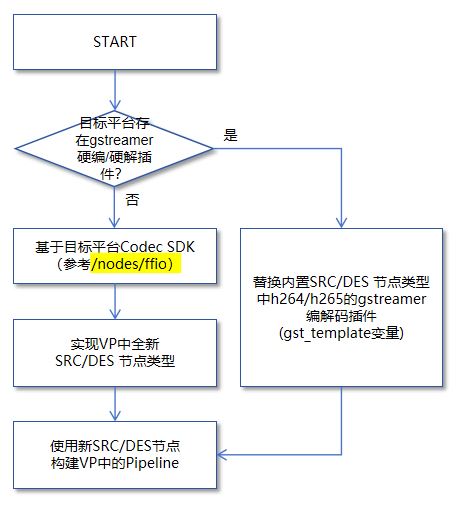
1、VideoPipe中的编解码部分默认采用Gstreamer管道实现,由OpenCV创建和加载Gstreamer编解码插件,如果你要适配的目标硬件平台本身有对应的GStreamer硬编解码插件,那么编解码移植这块的工作比较简单,直接替换原来软编解码插件为目标平台的硬编解码插件即可。如果没有现成的硬编解码插件可用(大部分时候是这种情况),那么你要做的工作就是参考仓库中/nodes/ffio这个目录中的代码(该目录基于FFmpeg实现了收流、拆包、解码、编码、封包、推流等逻辑),基于目标硬件平台的Codec编解码SDK,去实现自己的硬编、硬解逻辑,封装成VideoPipe中的一个SRC/DES Node即可,然后基于新的SRC/DES节点去构建VideoPipe中的Pipeline。
2、VideoPipe中的模型推理部分默认采用OpenCV::DNN模块实现,它可以加载主流深度学习框架导出的模型格式(如ONNX/Tensorflow/Caffe等),而且支持英伟达平台CUDA加速。当然针对英伟达平台,仓库中还提供了基于TensorRT推理后端的参考实现。如果你要适配其他硬件平台,那么需要基于对应硬件平台的推理Runtime去实现自己的推理逻辑,比如瑞芯微的RKNN、华为的CANN等等。这块其实很简单,直接参考硬件平台厂家提供的推理Demo代码,将其封装成VideoPipe中的一个推理Node即可,然后基于新的推理节点去构建VideoPipe中的Pipeline。
除了编解码和模型推理需要适配移植之外,其他比如OSD画图、颜色格式转换、图片缩放等环节可能也需要使用目标硬件平台的硬件加速API,这块可以参考模型推理移植的步骤,基于目标硬件平台提供的加速API实现对应逻辑即可(如瑞芯微平台的RGA图像处理加速库,专门处理图像缩放裁剪、格式转换等)。整个移植适配的工作其实相当简单,前提是你对适配的目标硬件平台要足够熟悉和了解。