[目录]
- 什么是文字接龙?
- 大模型如何做文字接龙?
- 什么是Token词元?
- 什么是Vocabulary词表?
- 什么是概率分布?
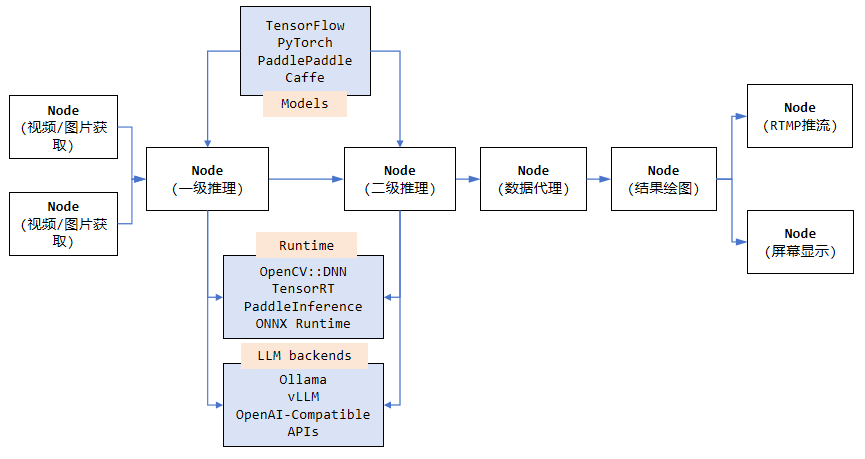
- 内部接龙流程
- 什么是Token计费
- 大模型训练方式和步骤
- 大模型有思考推理能力吗?
- 大模型擅长和不擅长的任务
- 大模型在Agent中扮演的角色
大语言模型(Large Language Model, LLM)听起来高深莫测,但如果剥去其复杂的外壳,它的核心逻辑其实非常朴素。本文将从七个维度,带你一步步揭开它的神秘面纱。注意本文以“大语言模型(LLM)”为例分析大模型工作原理,这类模型的输入输出皆为文本格式,对于其他支持多种格式(图片视频等)作为输入输出的“多模态大模型(MLLM)”的工作原理与之类似。
如果要用一句话概括大语言模型的本质,那就是:它是一个超级强大的“文字接龙”游戏玩家。文字接龙是一种简单又有趣的游戏,你写一个字、一个词或者一句话,下一步接着续写下去,尽量让语句合理连贯。举个例子:
(1) 玩家 A: “今天天气真好,”
(2) 玩家 B: “好想去公园散步,”
(3) 玩家 C: “步伐轻快,心情愉悦。”
每个人都是根据前面内容进行接龙,完成文字接龙游戏须具备两个前提:
(1) 玩家掌握基本的文法知识,比如熟悉中文语法、英文语法等,不至于在接龙过程中出现病句。
(2) 玩家掌握基本常识,熟悉世界知识,比如知道“天气好意味着适合外出散步”,否则各个玩家完全不同频,游戏无法进行。
大语言模型其实就是在做类似的“文字接龙”游戏,只不过规模大了无数倍(不限接龙主题、不限接龙语言、不限接龙领域,给什么接什么):
输入:你给大模型一段文字(Prompt/提示词)。
任务:它预测下一个最可能出现的字、词或符号是什么。
输出:把预测的字、词或符号加到原文后面作为输入,继续预测再下一个,直到出现结束符号。
如此循环往复,一个字一个字地蹦出来,最终形成了一篇通顺的文章、一段代码或一个故事。它并不真正“理解”输出文字的含义,它只是精通统计规律,知道在当前语境下(即Context),哪些字、词、符号组合在一起最“像”人类说的话。
既然大模型是在做接龙,那它是如何具体操作的呢?这里有几个关键概念:Token(词元) 和 概率分布等。
大模型并不是以“汉字”或“单词”作为最小单位来做文字接龙的,而是以另外一种叫做Token的结构。Token与汉字、单词、符号等并没有严格意义上的一对一关系。在英文中,一个Token 可能是一个完整的单词(如”apple”),也可能是词根(如”unchanged”中的前缀”un”),甚至是部分字母。在中文里,一个Token通常对应一个汉字(如“你”),也可能是常见的多字词(如“助手”、“是多少”),甚至一个汉字占2个Token。对于符号而言,可以与后面单词一起组成一个Token(如Python代码中常见的”__init”可以是一个独立的Token),也可以多个符号一起组成一个Token(如Python代码中的注释”####”可以是一个单独的Token)。还有一些特殊标记也被当做独立的Token(如句子开始,句子结束)。总之,在大模型领域中,Token是一种全新的结构,与我们常见的字、词、符号没有对应关系。
为什么要这么分? 因为这样能更高效地压缩信息,任何种类的语言文本可以被灵活组合拆分,让模型处理更长、更复杂的序列。你可以把Token理解为大模型眼中的“最小语义积木”,不同大模型的Token划分规则并不相同,比如LLama3中一共包含128000种Token,代表它每次预测输出可以有128000种可能。对于ChatGPT大模型,OpenAI提供一个在线工具可以查看它是如何划分Token的(https://platform.openai.com/tokenizer),任意输入一段文本,工具可以输出对应Token数量以及用颜色区分每个Token:
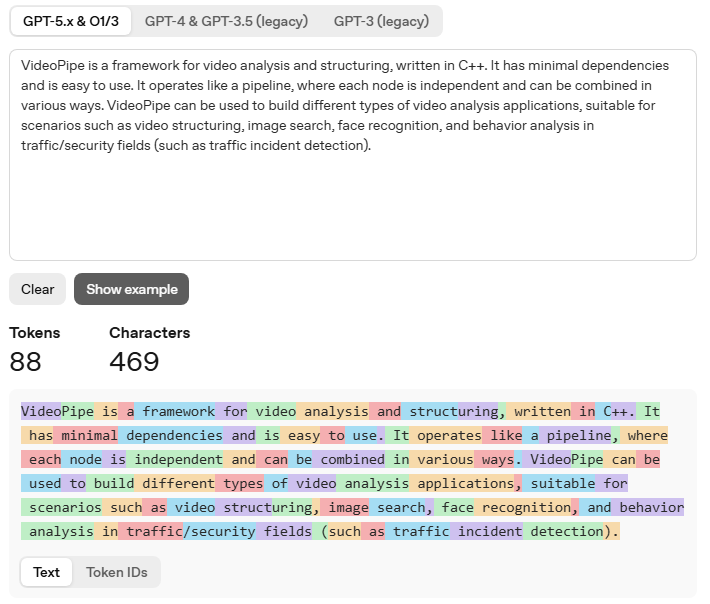
上面这段文本在GPT-5.X中被划分成88个Tokens进行处理,每个Token已用颜色区分。
不同大模型的Token划分规则并不相同,所以每种大模型支持输出的Token种类总数也不相同。LLama3能够输出128000种Token,Qwen2.5能够输出256000种Token,我们把模型能够输出的Token种类集合叫做词表(Vocabulary)。
如果对词表中的每个Token进行顺序编号,从零开始,LLama3的词表Token IDs取值范围为0~127999。在GPT-5.X中,刚才那段文本被划分成了88个Tokens进行处理,那么对应的Token IDs为(点击界面左下角Token IDs按钮):
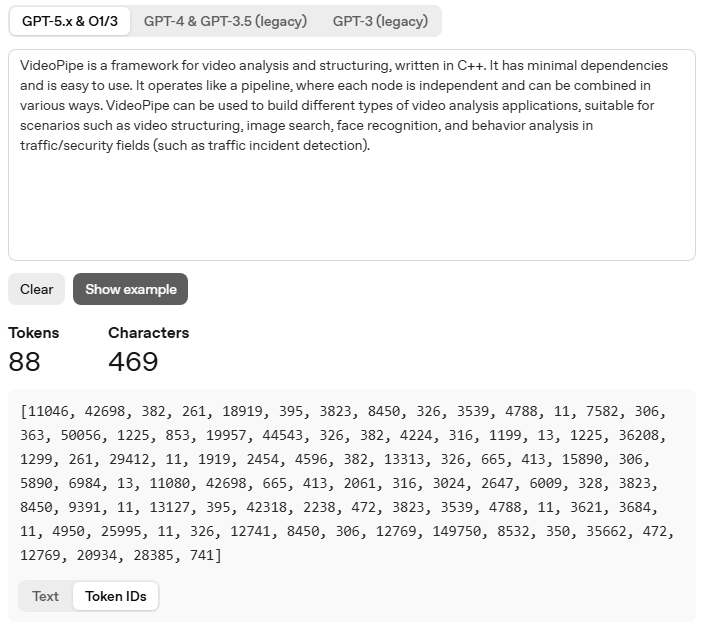
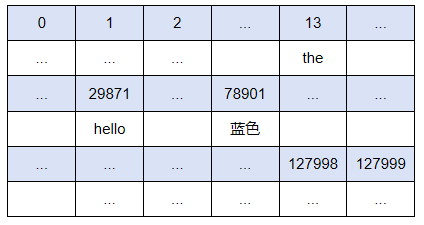
我们可以看到,在GPT-5.X中,这段文本开头的‘Video’作为一个独立的Token,它在词表中的ID为11046,即排在11047位(ID从零开始)。文本结尾‘).’被当做一个独立的Token,它在词表中的ID为741,排在742位。下面是词表示意图,蓝底为Token IDs,白底为对应Tokens:
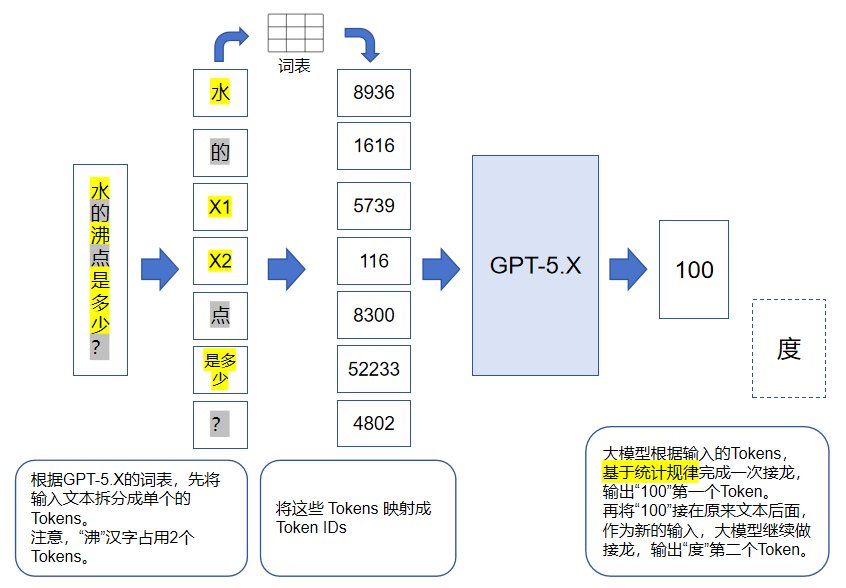
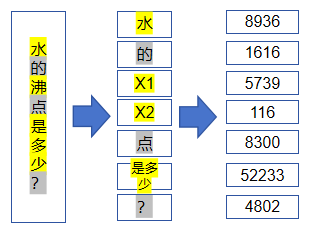
词表除了反映大模型能够输出哪些Token之外,还能辅助大模型对输入进行预处理。比如我们要给模型输入“水的沸点是多少?”时,由于大模型本身无法直接处理这些Unicode字符,所以需要我们先将这些文本拆分成Tokens,然后参考词表将它们映射成Token IDs,最后再送入大模型,示意图如下(注意是示意图,实际大模型可能并非输出类似答案):
总之,词表对于大模型的输入和输出环节都至关重要。输入环节要参考词表,输出环节也要参考词表。那么大模型的输出格式是什么呢?每次是直接输出Token ID,然后我们再做一次后处理:根据词表将Token ID映射成具体的Token吗?答案是否定的。要了解大模型的输出格式,我们需要先理解概率分布这个概念。
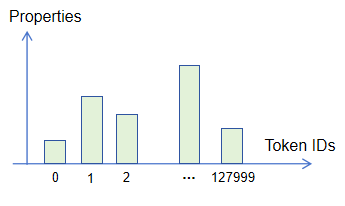
假如要设计一种算法或者系统,根据各种条件阈值,负责从有限集合范围内选择一个最符合预期的目标,你会如何设计这种系统的输出?在深度学习领域中,这种任务一般被称为“分类”任务,有限集合的大小即称作“分类数”。对于分类任务,深度学习算法一般输出一个概率分布(一组概率值,通常用一个数组表示),数组的大小即为分类数,这些概率之和为一,概率值越大、代表该分类命中的可能性越高。
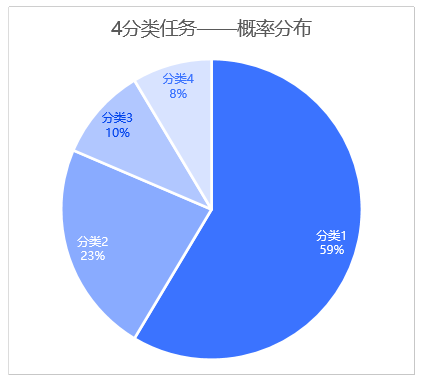
如上图所示,分类1(深蓝色部分)的概率值最大(0.59),因此根据概率分布的结果来看,分类1命中可能性最高,因此针对这个四分类任务,算法本次预测的结果是:分类1。
对CV计算机视觉熟悉的童鞋可能已经看出来了,CV中的图像分类是一种典型的“分类”任务,在基于深度学习的CV领域中,大部分用于图像分类的神经网络算法最终输出都是一个概率分布,即经过Softmax函数处理过后的概率向量,向量各维度概率之和为一(图片分类网络可以参考:http://www.videopipe.cool/index.php/2024/11/15/1-6/)。如果该分类算法用于ImageNet任务,那么它的分类数为1000,输出概率向量维度也为1000。下面是一个三分类的图像分类任务(猫/狗/鸡):
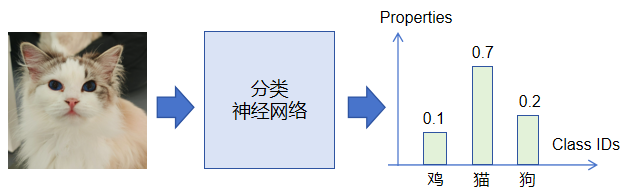
再回头来看大模型做文字接龙的这个任务,它本质上是一个Token分类任务。特别之处在于:
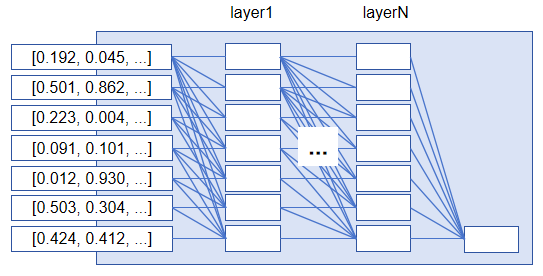
(1) 目标分类数非常之大,Llama3的词表大小为128000,所以分类数为128000。因此大模型每次都要输出一个超级大的概率向量,向量维度大小为128000。
(2) 用于Token分类的神经网络结构比较特殊,目前主流大模型均采用Transformer结构或其变种。同时由于目标分类数很大(意味着是一个复杂任务),神经网络包含超级大规模的参数量,通常需要用B(十亿)为单位来衡量,而传统小模型一般用M(百万)作为参数单位。
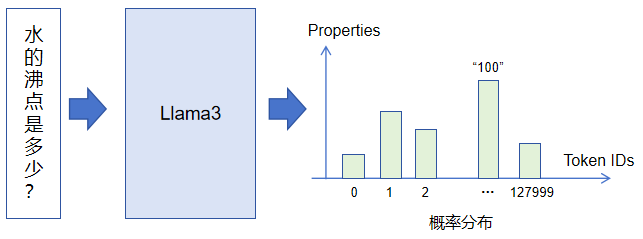
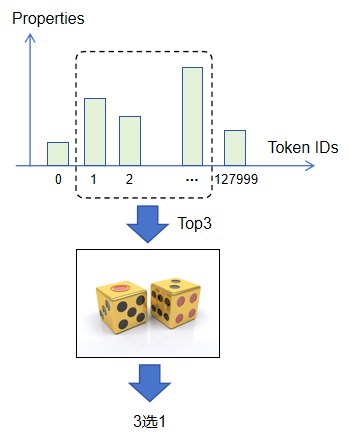
上图显示将“水的沸点是多少?”输入到Llama3模型中,模型单次推理输出第一个Token的结果示意图。它会输出一个超级大的概率向量,向量维度大小为Llama3词表大小,即128000,代表模型接龙输出Token的概率分布。那么,最终我们如何获取最终输出的Token呢?是直接取概率值最大的Token ID再映射回Token吗?直观上判断确实可以这样去做,但是为了提升大模型输出内容的多样性和灵活性(对于同一个输入,大模型每次推理输出不尽相同),实际并不是直接选取概率值最大的Token ID映射回Token,而是根据事先配置,选取概率值从大到小前Top K个Token IDs再根据一定规则“摇骰子”从中选取最终要输出的Token。正是因为这个机制,我们在使用豆包、ChatGPT等语言大模型的时候,对于同一个问题,每次回答都不一样。我们如果规定K为1,那么对于同一个输入,大模型每次的回答都相同(摇骰子失效)。
注意,由于大模型经过了大量数据进行Pre-Train预训练,因此我们选取的前Top K个Token IDs从统计经验规律来看,都可以当做正确Token被大模型输出,最终的输出内容看上去也都是合理连贯的。其实这很好理解,任何文字接龙本身并没有唯一答案,“摇骰子”这个动作正好实现了这个效果。
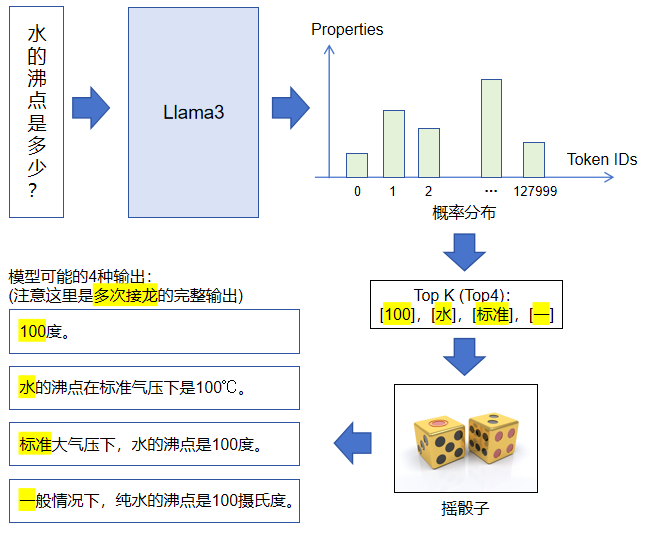
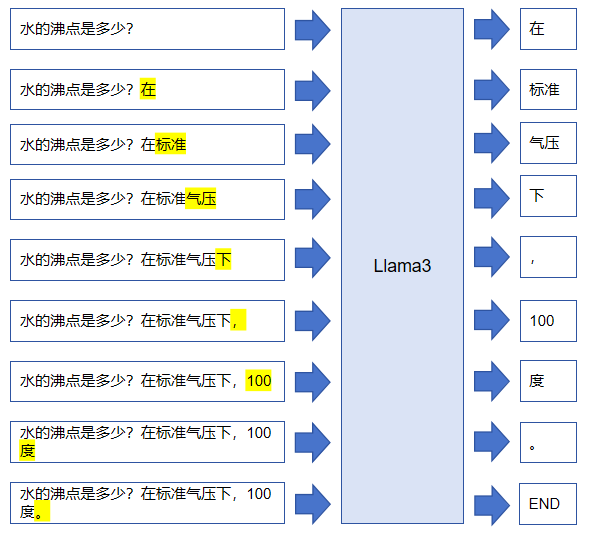
大模型每次推理输出一个Token,将每次输出的Token接在原来输入的尾部,再继续作为模型的输入,可以源源不断地得到连续的Tokens,直到模型输出【结束】标记。最后我们将所有的Tokens拼接在一起,作为模型的最终输出,可以是一句话、一首诗、甚至是一篇文章。
当你向大模型输入一段文本时(支持各种语言),会执行以下步骤:
词元化:根据模型预设词表,将文本拆分成单独的Tokens,然后再转换成Token IDs序列,这一步一般由Tokenizer完成,它是一种工具跟大模型本身无关。
向量化:所有的Token IDs被映射成对应的特征向量(Token Embedding)。这些特征向量捕捉了词语之间的语义关系(比如“国王”和“王后”在向量空间里的距离,与“男人”和“女人”的距离非常相似),Token Embedding由模型训练时期决定,属于大模型参数权重的一部分。关于特征向量的作用可以参考这里:http://www.videopipe.cool/index.php/2024/11/04/2/

注意力机制(Attention):这是大模型的“大脑核心”。针对每个Token,它会回头看前面所有的Tokens,计算当前要预测的Token与之前所有Tokens的相关性(下图中每个白色方块代表一个计算单元,每个计算单元的输入由它前面的Tokens共同决定)。例子:在句子“苹果很好吃,因为它很____”中,模型会注意到“苹果”和“好吃”,从而推断空白处填“甜”或“脆”的概率高于填“粉色”或“圆”,更要高于“蓝色”或“可爱”。
计算概率:模型会在其庞大的词表(可能有几十万个Tokens)中,为每个可能的下一个 Token 计算一个概率分数,得到概率分布。
采样选择:最后不会永远只选概率最高的那个Token(那样说话会很死板),而是根据概率分布进行“采样”(前面说的摇骰子)。有时候它会选概率第二、第三高的词(甚至其他,主要取决于你的配置),这让生成的文本更具多样性和创造性。
循环运行:将模型单次预测输出的Token接在原来输入的结尾,当做新的输入,给到大模型后,继续开始下一次Token接龙。直到大模型输出【结束】标记。需要注意的是,大模型每次接龙只能输出一个Token,对于需要输出大段文本的场合,大模型需要完成成千上万次接龙。显而易见,这里会出现一个性能问题,单次接龙已经很消耗算力了,成千上万次、而且输入Token数量越来越多,大模型如何应对这个问题?答案是利用键值缓存机制(KV Cache),因为每次接龙都是在上次的输入结尾增加一个新Token,其余的不变,所以大模型会缓存上一次接龙的部分计算结果,下一次接龙的时候直接使用缓存,避免每次重复计算,关于KV Cache概念本文不做太多讲述。
需要注意的是,上面举的例子都是给大模型输入一个完整问题(以问号结尾),让大模型输出问题答案。这主要是为了让大家直观理解接龙过程。实际上,大模型做文字接龙并不要求输入是一个完整的问题,输入任何内容都可以。比如给模型输入“今天天”,模型可以接“今天天气真好”,或者“今天天空有很多雾霾!”等等,至于接什么,要看具体的上下文(Prompt/Context),换句话说,大模型可以基于任何输入去续写后面的内容。
平时手机等移动设备使用5G上网,需要向网络服务提供商(电信/联通/移动)购买流量,流量单位一般使用MB和GB等,比如5元/GB。GB这种单位最开始是用来衡量计算机系统中文件(或数据)占用磁盘(或内存)空间大小,之后也用来表示网络数据传输多少。
与网络服务提供商类似,现在一些大模型公司(OpenAI/谷歌/阿里等)提供大模型基座服务,扮演大模型服务提供商的角色,为个人/公司/政府组织提供大模型能力,人们向模型提供商付费,使用事先定义好的接口协议获取大模型能力(给模型提供输入、获取模型的输出),从而为自己的软件系统、工作或生活赋能。大模型服务提供商一般以Token消耗数量来计费,比如10元/100万Tokens,当然也有包月套餐,这个跟5G流量包月类似。
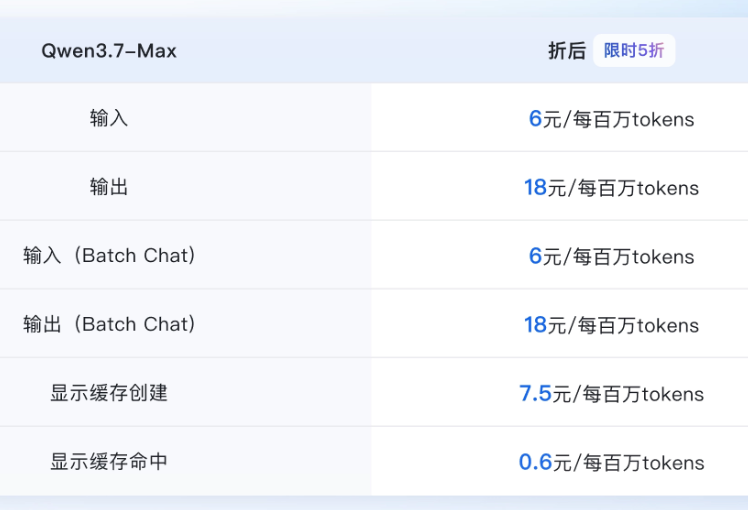
大模型的开发、训练、部署推理等基建门槛要求过高(技术/数据/算力),一般公司无法胜任,这也是为什么会出现类似的垄断性质的大模型服务提供商。需要注意的是,Token消耗量的统计并不完全透明,不同模型的词表规则并不相同,对于同一个输入和输出,A模型可能计算消耗100 Tokens,而B模型计算消耗120 Tokens。并且,Token消耗量完全由模型提供商给出,一般人很难通过自己的历史输入输出调用记录,去核实他们统计的准确性,因为对于那些频繁使用模型的人来讲,数据量太大导致这项工作实在太复杂。
大模型并非生来就聪明,它是通过“海量阅读”和“严格家教”训练出来的。训练过程通常分为三个主要阶段:
第一阶段:预训练(Pre-Training)—— 博览群书
(1) 目标:学习语言的基本语法规律、世界知识和逻辑结构,比如知道:“形容词后面接名词”、“一般用蓝色形容天空”、“1+1=后面接2比较合适”(注意不是计算)等等这些。
(2) 数据:互联网上的公开文本(网页、书籍、代码、论文等),数据量高达万亿级 Token。
(3) 方式:无监督学习。不需要人工标注答案。模型阅读前文,不断猜测下一个出现的词是什么,猜错则调整参数,猜对则强化记忆。这就像通过做无数道填空题,内化了语言和知识。这个原理跟深度学习领域中训练其他模型类似。
(4) 结果:得到一个“基座模型”(Base Model)。它“懂”很多知识,能续写(接龙)文字,但还不太会听话,可能会胡言乱语或无法遵循指令。
第二阶段:有监督微调(SFT, Supervised Fine-Tuning)—— 学习规矩
(1) 目标:让模型学会如何回答用户的问题,遵循指令。
(2) 数据:由高质量的人类专家编写的“问答对”数据集(例如:如何煮鸡蛋?给出回答详细的步骤)。与预训练相比,SFT需要的数据量要小得多,在万/十万数量级即可,核心要求是数据集的高质量。
(3) 方式:告诉模型,“当用户这样问时,你应该这样答”。
(4) 结果:模型变成了一个“助手”(Instruct/Chat Model),能够完成对话、总结、翻译等任务。
第三阶段:人类反馈强化学习(RLHF)—— 对齐价值观
(1) 目标:让模型的回答更符合人类的偏好(有用、诚实、无害)。
(2) 方式:模型生成多个回答。人类评估员对这些回答进行排名(哪个更好,哪个有偏见,哪个不安全)。训练一个“奖励模型”来模仿人类的评判标准。利用强化学习算法,根据奖励模型的反馈进一步优化大模型。
(3) 结果:模型变得更安全、更有礼貌,且更符合人类的道德和法律规范。
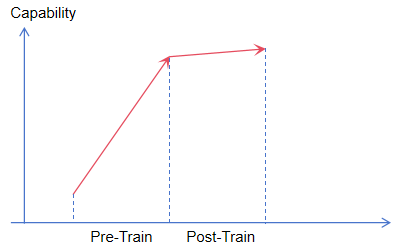
阶段一称为预训练Pre-Train,阶段二和三(或者还有其他手段)一般统称为后训练Post-Train。研究普遍认为,模型的知识储备和“智力”上限主要由预训练阶段的数据规模和质量决定。SFT和RLHF阶段主要作用是“解锁”这些能力,并将其引导至符合人类需求的行为模式上。可以说,预训练决定了模型“有多聪明”,而后训练决定了模型“有多好用”,在预训练阶段没有接触过的资料知识(比如某个特定领域),一般很难通过后训练让模型掌握。
很多人以为大模型像人一样“思考”,其实它的本质是统计预测,不是像人类有意识的思考:
(1) 模型做的是概率计算:基于已有文本(输入Context),计算后面每个Token出现的概率,选择最可能的输出。
(2) 表现像推理:当模型回答问题或写文章时,它会参考大量训练经验(由模型参数权重决定),生成符合逻辑的文本,看起来像“推理”。
(3) 局限性:模型不会真正理解世界,也不会有自我意识,它的“推理”仅仅是模式匹配和概率计算的结果。
可以把它想象成一个非常聪明的模仿者:它能模拟合理逻辑,但不是真的在思考。大模型本质上一直在做文字接龙(续写),而且只能根据统计规律去完成这个游戏,比如当它遇到“1+1=”的时候,会根据统计规律输出“2”,并不像人类那样在脑子里面通过四则运算、或者推演得出结果。这也是为什么大模型不擅长处理需要精准计算的任务,比如分析一张复杂的Excel数据报表、以及完成高维的数独游戏,因为这些任务每一步都涉及到精确计算,大模型一步接龙出错,后面会步步错。反观其他任务,比如让大模型写诗,“僧__月下门”中间填“推”和“敲”都可以,无伤大雅,如果没有其他上下文作为限制时,甚至还可以填“关”。
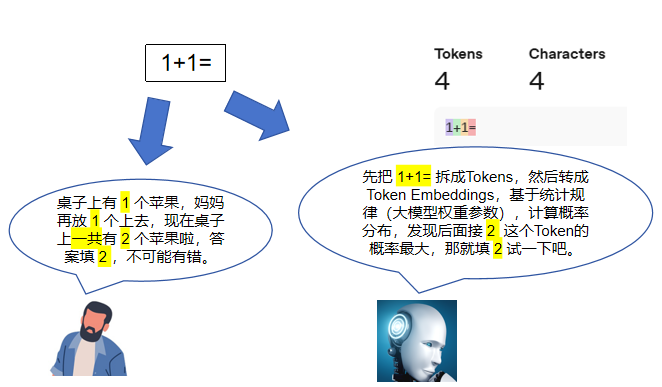
需要注意的是,本文提到的“思考推理”是指类似人类高级动物具备的能力,大模型当然可以“表现”出思考推理过程,比如当你选择Thinking模式,在正式输出结果之前,它会先输出一大段所谓的CoT(Chain Of Thought),像是模型的内心戏,但这仍然是基于概率统计在做文字接龙,内心戏会进一步丰富输入Context,有利于后面正式输出时的文字接龙,从而提升输出结果的合理性,这与人类思考过程完全不是一个东西。
根据前面介绍的大模型工作原理,其实很好归纳它的优劣势,从而判断它擅长和不擅长的任务:
擅长的任务:
(1) 写文章、编故事、写邮件、写代码
(2) 总结文章、提取信息
(3) 语言翻译、句子改写润色
(4) 对话聊天、生成连贯回复
(5) 做方案、制定计划
不擅长的任务:
(1) 真正的因果推理和科学推导
(2) 精确计算或逻辑推理验证
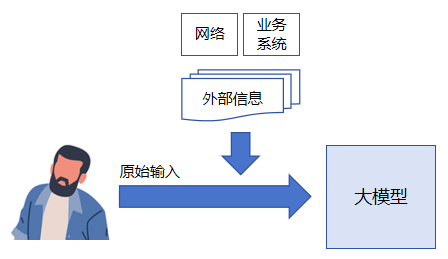
(3) 需要基于训练数据之外的信息(外部数据/实时信息/模型训练时没接触到的知识)
注意上面不擅长的任务不代表模型完全不能做,而是受限于模型工作机制原理,大模型很难做好这些任务。其中第三条,大模型无法知道在它训练数据之外的信息,比如一个模型在2025年10月份训练完成(模型权重参数已确定,用于统计规律的经验已经固化),它掌握的信息最晚到2025年10月份。因此你问它关于2025年10月份之后发生的新闻事件,它可能也会给你一个回答,但是大概率是错的。或者问它跟天气、股票相关的实时信息,大模型本身也无法准确回答这类问题,这时候就需要借助外部工具,比如Browser Use、Computer Use之类的工具,通过这类工具收集实时天气、股票信息作为输入上下文(Context)一起给到模型,提升后续大模型文字接龙的正确性。前几年很流行的RAG(检索增强生成)技术就是为了更好的弥补大模型这种先天性不足的缺陷。
总之,大模型想要做好一件事,必须有两个前提:
(1) 不能超出文字接龙这个规则,比如需要精准计算的就不太行,它不是光靠基于统计规律的文字接龙就能搞得定的
(2) 不能超出模型训练时所掌握的信息范围,否则就要想办法提供丰富的输入上下文一起给到模型
关于如何让大模型发挥更大功能和作用,弥补其先天性缺陷,参见本文后面介绍智能体的相关内容。
在大模型(如 ChatGPT3.5)流行之后一段时间,AI 应用逐渐从简单的“对话问答”模式,演进到更加复杂的“任务执行”模式。在 2022 年底到 2023 年期间,大模型主要以聊天界面的形式出现,用户通过“一问一答”的方式与模型交互。为了提升输出的准确性与稳定性(更好地完成接龙),人们开始研究如何设计更有效的输入,这也催生了所谓的“Prompt 提示词工程”。然而,随着应用的深入,人们逐渐发现:尽管大模型在语言理解和生成方面表现出色,但它本质上仍然只是一个“推理与生成引擎”。它可以给出建议、提供思路,却缺乏与外部环境交互和实际执行任务的能力,对于自己不擅长的任务无能为力(参见本文前面介绍)。它无法主动访问互联网获取最新信息,也无法直接调用工具处理数据或完成具体操作。
在这样的背景下,“AI智能体(AI Agent)”这一范式开始受到广泛关注。可以将其理解为一种以大模型为核心的应用系统:其中,大模型相当于“决策中枢”,负责理解任务、制定计划和做出判断;而智能体系统则负责调用工具、访问数据、执行操作,并将结果反馈作为输入给大模型,形成一个“感知—决策—执行—反馈”的闭环。
例如,在一个典型的智能体系统中,大模型可以判断是否需要联网搜索信息,是否需要调用代码执行环境分析数据,或者是否需要读取本地文件。智能体将每一步执行的结果都会再次输入给模型,用于决定下一步行动,从而逐步完成复杂任务。
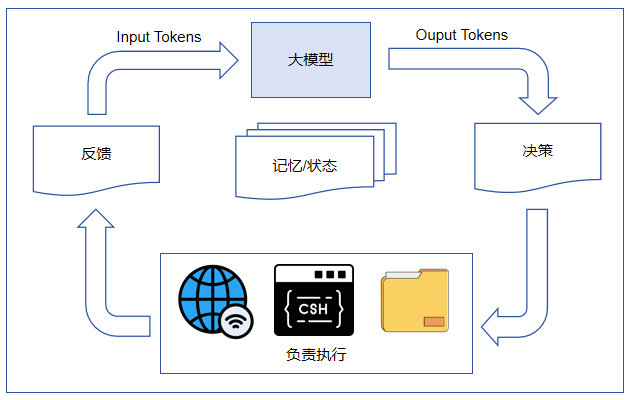
此外,作为工程化系统,AI智能体通常还具备“记忆(Memory)”和“状态管理(State Management)”能力,可以在多轮任务中保留上下文信息。这种机制在很大程度上将原本依赖人工设计的 Prompt 工程进行了系统化封装,使开发者可以更专注于任务本身。
总体来看,AI智能体并不是取代大模型,而是在其基础上进行能力扩展,使其从一个“对话工具”演变为一个能够理解目标、规划步骤并执行任务的智能助手。