VideoPipe是一个用于视频分析和结构化的框架,采用 C++ 编写、依赖少、易上手。它像管道一样,其中每个节点相互独立并可自行搭配,VideoPipe可用来构建不同类型的视频分析应用,适用于视频结构化、图片搜索、人脸识别、交通/安防领域的行为分析(如交通事件检测)等场景。
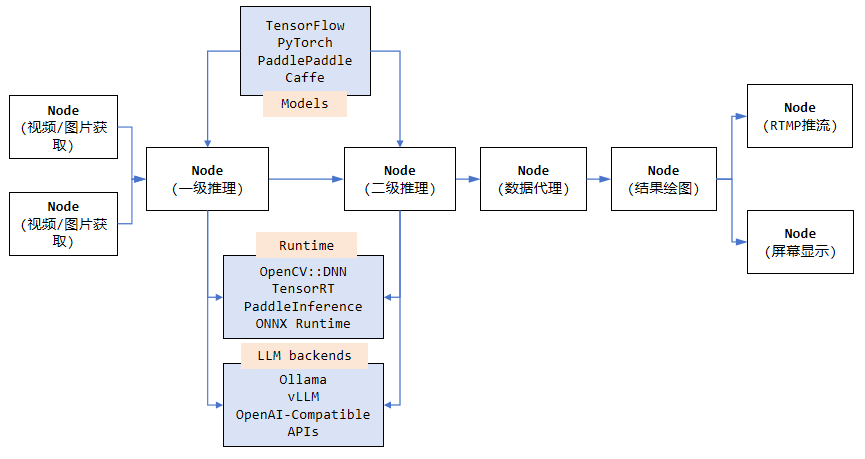
VideoPipe项目仓库中已经提供了50多个集成传统AI算法模型的Sample源码,涉及到车牌识别、人脸识别、违章检测、图搜、OCR、AI变脸、目标检测、图像分类、图像分割等各个领域。在大模型逐渐成为主流的今天(多模态大模型赋能传统AI视觉算法领域中表现优秀),VideoPipe也支持大模型集成啦,这次重点介绍VideoPipe如何集成多模态大模型来完成视频(图片)分析相关任务。
快速开始
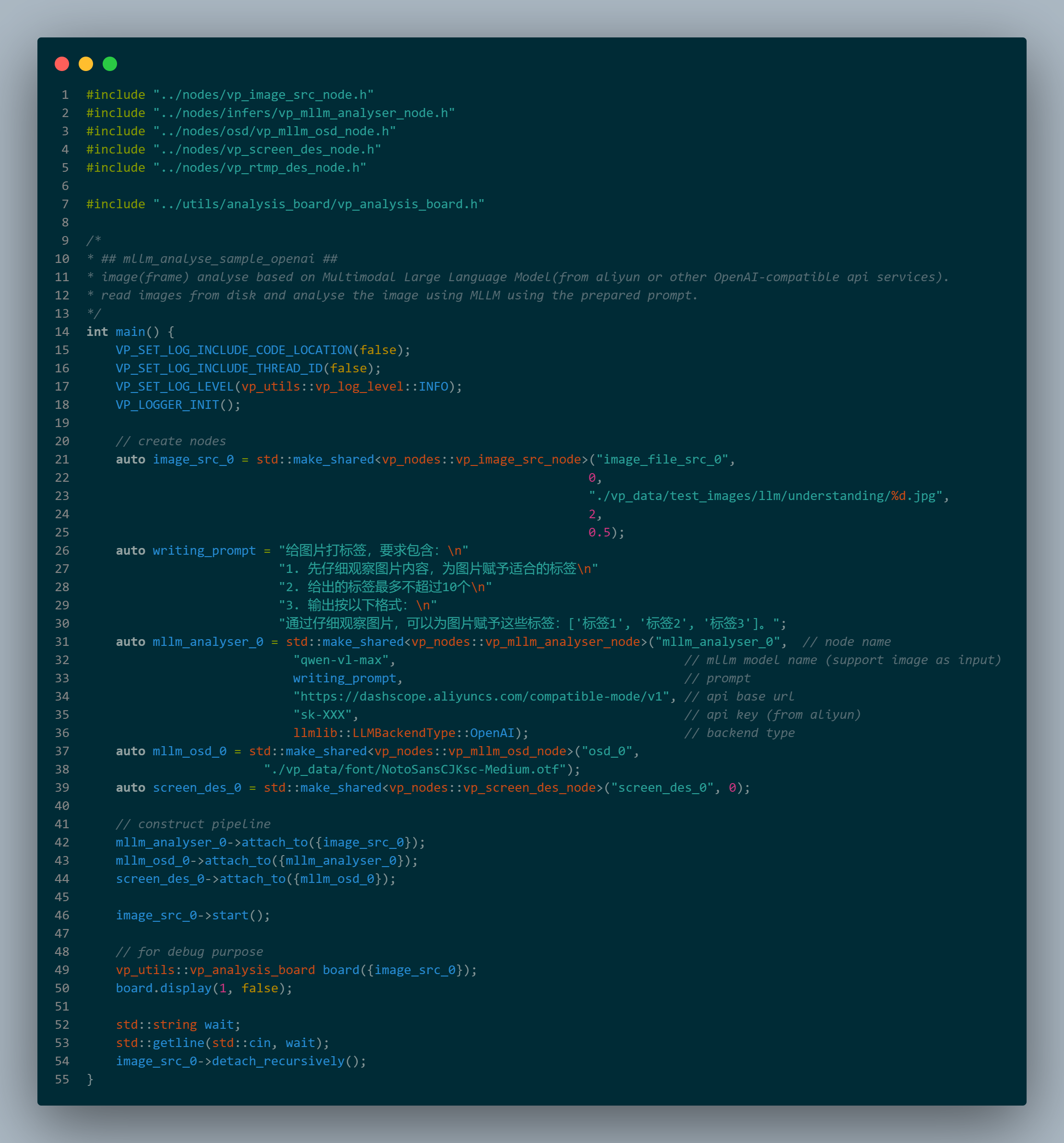
下面基于VideoPipe和阿里云qwen-vl多模态大模型实现一个简单的图片理解的功能:从本地磁盘读取图片序列(现实场景中可以从网络获取图片或视频数据),大模型根据事先定义的Prompt提示词,对图片进行识别理解,依次对图片进行标签化,然后将标签化结果叠加到图片下方,最后显示结果。
1、创建VideoPipe节点类型(事先准备好aliyun大模型服务api_key)
2、将节点串起来,组成Pipeline管道
3、启动管道(一共55行代码)
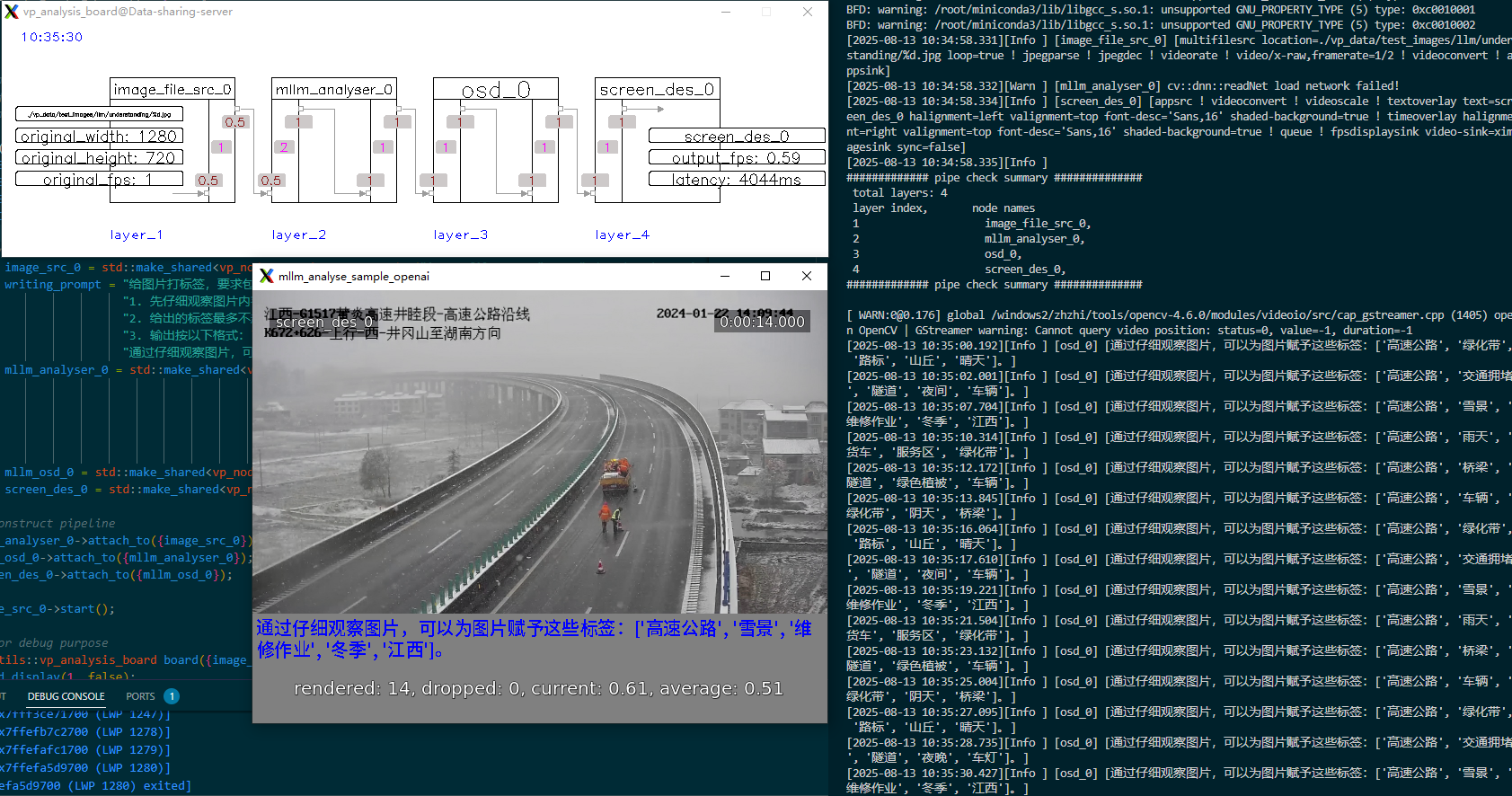
运行效果
管道运行起来之后,大模型分析节点根据事先定义好的参数(模型名称、提示词、api_key)访问大模型服务,并解析大模型输出,随后显示节点将大模型输出绘制到图片中,并在控制台实时打印。VideoPipe目前支持的大模型后端有:OpenAI协议兼容服务、Ollama/vLLM本地部署服务。